

Due to its similarity to the English language, Python is well known for being easy to learn and comprehend, making it a popular language among both novices and experts. However, in terms of execution it might not necessarily be the quickest. Thankfully, you can use a number of techniques to optimize your Python code for increased efficiency. This article will go over helpful tips that programmers can use to improve the efficiency of their Python code.
Understanding Python’s Performance Characteristics
The fact that Python is an interpreted language is one of its primary features and points of differentiation. Python code does not need to be pre-compiled into machine code in order to be run directly. This speeds up Python development considerably. However it has its drawbacks.
- Interpreted Language: Because Python is an interpreted language, every time it is run on a processor, its code must be interpreted. The interpreter runs the code line by line. This might operate more slowly than compiled languages, which would lengthen the time to market and cause performance to lag.
2. Dynamic Typing: This technique can be useful for supporting numerous variable types, but it can also result in type checking delays and runtime issues.
3. Memory Consumption: Python can use a lot of memory, particularly if your software processes big amounts of data.
We can see that the performance of Python is a trade-off between speed and ease of use. It’s not the fastest language, but it’s still a very flexible programming language that can be made to run faster by adhering to a few best practices.
Key Data Structure Choices for Efficiency
Python offers a wide variety of rich data structures like dictionaries, lists, tuples and sets. You may greatly increase your overall Python performance by knowing which data structure to utilize when. Following are the examples in which you should use certain data structures.
- Lists: it is acceptable to have duplicate data in lists and it should be used to maintain the order of elements. It is also helpful when doing actions like removing, adding, or inserting items, or when you require indexed access to elements
- Sets: Unsorted groupings of distinct components are called sets. As well as mathematical operations like intersection and union, sets are frequently utilized for membership testing and for eliminating duplicates from lists. You can declare them with the set() constructor or with curly braces {}.
- Dictionaries: An unordered set of key-value pairs is called a dictionary. A popular usage for dictionaries is sorting, counting, and lookups. Their keys and values are separated by a colon (:), and they are defined with curly braces {}.
- Tuples: An ordered set of elements is called a tuple. Lists and tuples are similar in that tuples’ elements cannot be changed once they are produced. Parentheses() or the tuple() constructor are used to define them.
Numerous problems can be solved using these data structures in a number of ways. Assume, for instance, that we wish to create a software that keeps track of the character frequency in a given string and records the outcome in a data structure. We’ll contrast utilizing a list and a dictionary as shown in figure 1 and 2.
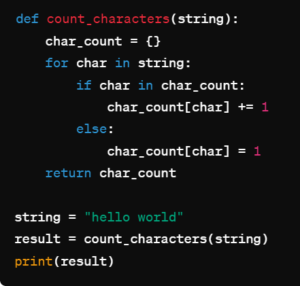
Figure 1: Dictionary for Counting
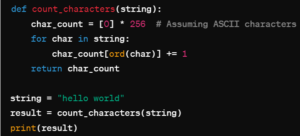
Figure 2: List for Counting
- Figure 1: Characters are used as keys and their frequencies as values in the dictionary approach. Because of this, we can access and update the count for each character directly in an average amount of time, giving us an O(n) time complexity, where n is the string’s length.
- In the list technique, the count of each character is stored in a list of fixed size (256, assuming ASCII characters). The character’s ASCII value serves as the list index. Although this method can be effective, it uses more memory since it preallocates space for every character that could possibly exist. Moreover, changing the count requires accessing the list by index, which can take a long time. As a result, this method’s time complexity is similarly O(n), however indexing may cause it to use more memory and have slower access times.
For jobs that require counting or keeping associations between keys and values, utilizing a dictionary is generally more effective and simple.
Remember that every data structure has advantages and disadvantages of its own, and that selecting the best data structure for a given task can significantly increase code readability and efficiency.
Advanced Python Features for Optimal Performance
Python offers a plethora of built-in functions and methods for efficient data manipulation. Here are some advanced techniques for working with these data types:
- String formatting: Utilize `format()` method or f-strings for dynamic value insertion.
- Regular expressions: Harness the `re` module for versatile string operations like pattern matching.
- String methods: Employ methods like `.strip()`, `.split()`, `.replace()` for string manipulation.
- Number formatting: Leverage `format()` method or f-strings to control decimal places and formatting options.
- Type casting: Convert between data types using `int()`, `float()`, `str()` functions.
- Decimal precision: Use Python’s `decimal` module for high-precision decimal arithmetic, beneficial for financial calculations.
- Advanced math: Explore Python’s `math` module for trigonometric, logarithmic, and exponential functions, or `NumPy` for more extensive mathematical operations, especially with arrays and matrices.
By applying these techniques, you can efficiently manipulate strings, numbers, and other data types, enhancing code readability and performance. Testing and benchmarking your code are vital, particularly with large datasets, to ensure optimal efficiency.
Profiling and Optimizing Python Code
Software profiling is the act of gathering and examining different program metrics in order to pinpoint “hot spots,” or areas of performance bottlenecks. Many factors, such as excessive memory use, insufficient CPU utilization, or an inadequate data layout, can cause these hot spots, which will increase latency by frequently causing cache misses. A variety of continuous profilers from the active Python development community can be useful.
Generally speaking, whenever you’re thinking about optimization, you should profile your code first to determine which bottlenecks need to be fixed. If not, you can end up chasing the incorrect beast. But, you won’t be able to determine with certainty whether sections of the code are worth changing without factual data obtained from a profiler tool. Below are most popular Python profiling tools and concepts:
- Timers like the time and timeit standard library modules, or the codetiming third-party package
- Deterministic profilers like profile, cProfile, and line_profiler
- Statistical profilers like Pyinstrument and the Linux perf profile
Leveraging Python’s Built-in Functions and Libraries
An extensive ecosystem of built-in libraries in Python allows for analysis and manipulation of data. Among these libraries are:
• NumPy: NumPy is a library for manipulating big numerical data matrices and arrays. It offers functions that can be used to carry out statistical analysis, Fourier transforms, and linear algebra on these arrays.
Scikit-learn: This is a machine learning library. For applications like dimensionality reduction, clustering, regression, and classification, it offers a large selection of algorithms. It also comes with preprocessing, assessment, and model selection tools.
• Pandas: Data in a CSV file or other tabular format can be worked with using the Pandas library. It offers data structures that make data management and analysis simple, like the DataFrame and Series. Additionally, pandas has functions for reading and writing information from a variety of file formats, including SQL, Excel, and CSV.
• Seaborn: a library that offers a high-level interface for producing stunning and educational statistical visualizations, Seaborn is developed on top of Matplotlib. It also offers tools for displaying intricate interactions between several variables.
• SciPy: SciPy is a library containing methods for interpolation, integration, optimization, signal and picture processing, and more
Without needing to write low-level code, you may quickly and simply do complicated data analysis and manipulation tasks with these libraries.
A function that is already present in the library shouldn’t be manually written. The functionalities of libraries prove to be highly effective. It’s actually not easy to match this degree of efficiency in your own code. Additionally, using them undoubtedly saves you a ton of time. Figure 3 lists some of the python built-in functions.
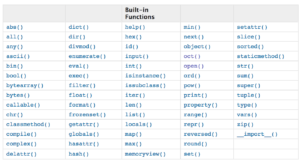
Figure 3: List of Python built-in Functions
The Role of Multithreading and Multiprocessing
The concurrent execution of tasks is made possible via the multithreading and multiprocessing modules in Python, which improve efficiency:
Multithreading:
- Concurrency: enables the concurrent operation of several threads within a single process, making it appropriate for I/O-bound tasks.
- Common Memory: Sharing memory space across threads makes synchronization and communication easier.
Multiprocessing:
- True Parallelism: Allows for the simultaneous execution of several processes, avoiding the need for the Global Interpreter Lock when dealing with CPU-bound activities.
- Isolation: The independence of the processes improves fault tolerance and stability.
Both strategies make use of several CPU cores, scale with hardware capabilities, and increase efficiency through efficient task distribution, shorter execution times overall, and higher system throughput.
Effective I/O Operations in Python
By implementing these strategies, Python developers can optimize I/O operations for improved code efficiency.
- Batch processing: To cut down on overhead, handle data in sections as opposed to one at a time.
- Buffering: To improve performance, particularly for file operations, read or write data in bigger chunks.
- Asynchronous I/O: Use libraries like asyncio to carry out several I/O operations at once without interfering with other jobs.
- Memory Mapping: Direct file mapping into RAM allows for quicker access and lower overhead.
- Compressed File Operations: To expedite read/write operations, particularly for big datasets, compress files prior to I/O operations.
- Optimized File Formats: For improved I/O efficiency, select effective file formats such as CSV, JSON, or Parquet.
- Caching: To minimize the requirement for repetitive I/O operations, cache data that is frequently retrieved in memory.
- Parallelism: Make use of multiprocessing or concurrent.futures libraries to achieve parallelism for I/O-bound operations.
FAQS
Q1) What are the best practices for improving Python code efficiency?
To improve Python code efficiency, programmers can follow several best practices outlined in the article. Firstly, understanding Python’s performance characteristics is crucial. While Python’s interpreted nature offers ease of use, it may lead to slower execution compared to compiled languages. Programmers should be mindful of dynamic typing and memory consumption, optimizing code accordingly. Selecting appropriate data structures such as dictionaries, lists, sets, and tuples can significantly impact efficiency. For instance, dictionaries are efficient for tasks like counting and lookups, while sets are suitable for membership testing and duplicate removal. Additionally, leveraging advanced Python features like string formatting, regular expressions, and number formatting enhances code performance. Profiling and optimizing code using tools like timers, deterministic and statistical profilers, and leveraging built-in libraries such as NumPy, Pandas, and SciPy further contribute to efficiency improvements.
Q2) How can Python programmers utilize built-in functions for better performance?
Python programmers can take advantage of the large ecosystem at their disposal to optimize performance by utilizing built-in functions and libraries. Large numerical data arrays can be efficiently worked with by libraries like NumPy, while Pandas makes data administration and analytical chores easier. SciPy offers techniques for interpolation, integration, optimization, and other tasks, whereas Seaborn offers high-level interfaces for creating educational statistical visualizations. Programmers can save time and avoid writing low-level code by using these libraries to effectively complete difficult data analysis and manipulation tasks.








